마케터라면 누구나 한 번쯤
"이번에 새로 도입한 B안이랑 C안 중에서 뭐가 진짜 효율이 좋은 거지?",
"광고비를 늘리면 매출이 정말 정비례해서 오를까?"라는 고민에 빠지게 됩니다.
그로스마케터의 핵심은 ‘느낌’이 아닌 데이터 분석에 의한 ‘통계적 증거’로 움직이는 것입니다.
오늘은 파이썬(Python)을 활용해 A/B/C 세 가지 광고 캠페인의 100일간 일별 광고비와 매출 데이터를 분석하고,
ANOVA(분산분석)와 상관분석을 통해 최적의 의사결정을 내리는 실습 과정을 공유합니다.
실습 1. ANOVA (일원분산분석)
그로스마케팅 실험을 진행하다 보면 3개 이상의 캠페인 성과를 한 번에 비교해야 할 때가 많습니다.
ANOVA는 3개 이상 집단의 분산에 대한 평균 차이를 분석하는 통계 기법입니다.
- 귀무가설(H0): 모든 마케팅 캠페인(A, B, C안)의 평균 매출은 같다.
- 대립가설(H1): 적어도 한 쌍 이상의 캠페인 간에는 평균 매출의 차이가 있다.
파이썬의 scipy.stats 라이브러리를 활용해 일원분산분석(f_oneway)을 아주 간단하게 실행할 수 있습니다.
# 그룹 a, b, c의 평균 차이를 구하는 아노바 분석 후 유의확률을 p_val_f에 저장
_, p_val_f = stats.f_oneway(group_a, group_b, group_c)
print(f"▶ 유의확률(p-value): {p_val_f:.4f}")
print(f"A안 평균 매출: {group_a.mean():,.0f}원")
print(f"B안 평균 매출: {group_b.mean():,.0f}원")
print(f"C안 평균 매출: {group_c.mean():,.0f}원")
분석 결과 출력
▶ 유의확률(p-value): 0.0000
A안 평균 매출: 4,530,056원
B안 평균 매출: 4,702,016원
C안 평균 매출: 5,056,951원
결과 해석: 유의확률(p-value)이 0.05 미만(0.0000)으로 나타났습니다.
즉, 세 그룹 중 적어도 한 쌍 이상은 통계적으로 확실히 유의미하게 다른 평균 매출 수치를 보인다고 결론을 내릴 수 있습니다.
- 어떤 안이 얼마나 차이가 날까? 사후분석 (Tukey HSD)
하지만 ANOVA 분석만으로는 'A, B, C 중
정확히 어떤 그룹끼리 차이가 나는지' 알 수 없습니다.
마케터로서 명확한 의사결정을 내리기 위해 다중 검정의 리스크를 보정한
Tukey의 사후분석(Post-hoc 완료)을 함께 진행해 줘야 합니다.
파이썬 statsmodels 패키지의 pairwise_tukeyhsd 함수를 사용해 한눈에 볼 수 있는 요약 표를 만들어 보겠습니다.
from statsmodels.stats.multicomp import pairwise_tukeyhsd
# ANOVA 적용 후 어떤 그룹이 얼마만큼 차이가 나는지 상세 확인
tukey_result = pairwise_tukeyhsd(
endog=df["Revenue"], # 결과 데이터 (매출액)
groups=df["Group"], # 구분할 기준 (A/B/C안)
alpha=0.05 # 다중검정을 포함한 오차 허용 기준선 (5%)
)
tukey_result.summary()
사후분석 결과 표 요약
결론: C안을 적극채택하는 것이 좋음
| group1 | group2 | meandiff (평균차이) | p-adj (보정 p-value) | reject (차이 여부) |
| A_안(기존) | B_안(신규1) | 171,960.0 | 0.0533 | False (차이 크지 않음) |
| A_안(기존) | C_안(신규2) | 526,895.0 | 0.0000 | True (확실히 차이남) |
| B_안(신규1) | C_안(신규2) | 354,935.0 | 0.0000 | True (확실히 차이남) |
실습 2. 상관분석
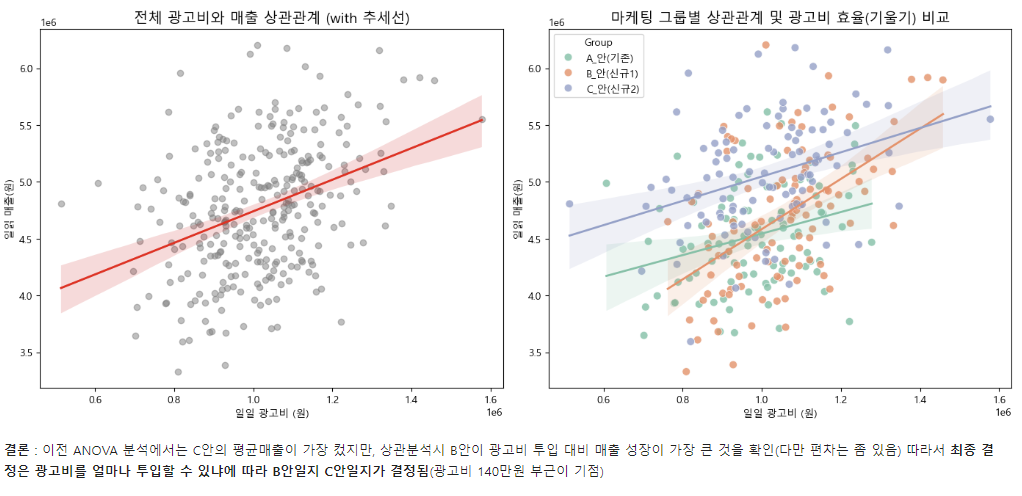
앞서 ANOVA를 통해 ‘C안(신규2)’ 캠페인이 평균적으로 가장 높은 매출을 올린다는 것을 검증했습니다.
하지만 그로스마케터라면 여기서 한 발짝 더 나아가야 합니다.
"C안이 평균 매출은 높은데... 과연 광고비를 추가로 투입했을 때도 가장 폭발적으로 성장할까?"
이 의문을 해결하기 위해 마케팅의 핵심 지표인 일별 광고비(Ad_Spend)와 매출액(Revenue)의 관계를 파악하는 상관분석을 진행해 보겠습니다.
파이썬 scipy.stats 라이브러리의 pearsonr 함수를 사용하면 두 변수 간의 관계의 강도(상관계수r)와 통계적 유의미함(p-value)을 단 두 줄로 뽑아낼 수 있습니다.
# 광고비와 매출액 간의 피어슨 상관계수 산출
corr, p_val_corr = stats.pearsonr(df["Ad_Spend"], df["Revenue"])
print(f"▶ 유의확률(p-value): {p_val_corr:.4f}")
print(f"전체 데이터 상관계수(r): {corr:.4f}")
분석 결과 해석 (전체 데이터 기준)
▶ 유의확률(p-value): 0.0000
전체 데이터 상관계수(r): 0.3688
결과 해석: 유의확률(p-value)이 0.05 미만(0.0000)이므로 이 상관관계는 우연이 아닙니다. 상관계수 r 값이 0.3688로 나타난 것은 광고비와 매출 간에 ‘유의미한 약한 양의 상관관계’가 성립한다는 뜻입니다.
결론 시각화
# 시각화
# fig:도화지 전체, axes:분리된 도화지 방들 , plt.subplots(1, 2, ...) 도화지의 화면을 가로로 2개의 방으로 쪼개 , figsize=(14,6) 가로 14, 세로
fig, axes = plt.subplots(1,2, figsize=(14,6))
# [좌측 그래프]: 전체 광고비와 매출의 상관관계(추세선 포함)
# regplot(Regresstion Plot): 산점도 위에 추세선(회귀선)을 자동으로 그려주는 함수
# data=df, x="Ad_Spend", y="Revenue": 엑셀 표(df)에서 가로축(X)은 광고비, 세로축(Y)은 매출로 설정합니다.
#ax=axes[0]: 방금 쪼갠 도화지 중 0번째 방(왼쪽 방)에 이 그래프를 그리라고 지정하는 것입니다.
# scatter_kws={...}: 그려지는 점들의 스타일입니다. 색상은 회색("gray"), 투명도는 50%("alpha": 0.5)로 주어 점들이 너무 튀지 않게 조절
#line_kws={...}: 추세선(선)의 스타일입니다. 눈에 잘 띄도록 빨간색("red"), 두께는 2("linewidth": 2)로 설정
sns.regplot(
data=df,
x="Ad_Spend",
y= "Revenue",
ax=axes[0],
scatter_kws={"alpha": 0.5, "color":"gray"}, #표시되는 점(데이터)들의 세부사항 설정
line_kws={"color": "red", "linewidth": 2} #추세선의 세부사항 설정
)
axes[0].set_title("전체 광고비와 매출 상관관계 (with 추세선)", fontsize=14)
axes[0].set_xlabel("일일 광고비 (원)")
axes[0].set_ylabel("일일 매출(원)")
#[우측 그래프]: 각 마케팅 그룹별 광고비와 매출 산점도 및 추세선
# scatterplot: 산점도 그래프
# hue="Group": ★매우 중요★ 그룹별로 점의 색상을 다르게 칠해라라는 뜻입니다
# alpha=0.8, s=60: 점들의 투명도는 80%로 살짝 주고, 점의 크기(s, size)는 60으로 보기 좋게 키웠습니다.
sns.scatterplot(
data=df,
x="Ad_Spend",
y= "Revenue",
ax=axes[1],
hue="Group",
palette="Set2",
alpha=0.8, # 점들의 투명도
s=60, # 점 크기
)
# 각 그룹별로 추세선을 따로따로 그려서 그래프에 추가하기
groups=df["Group"].unique() #3개안들의 유니크 값
colors = sns.color_palette("Set2", len(groups)) #산점도와 동일한 색상표(set2)와 GROUP 개수 사용
for idx, group in enumerate(groups) :
subset = df[df["Group"]==group] #각 그룹의 불리언 인덱싱
# =참 거짓을 판별하는 조건문
sns.regplot( # 변수 = 데이터프레임[데이터프레임['기준컬럼'] 조건연산자 기준값]
data=subset,
x="Ad_Spend",
y= "Revenue",
ax=axes[1],
scatter=False,
color=colors[idx],
line_kws={"linewidth":2}
)
axes[1].set_title("마케팅 그룹별 상관관계 및 광고비 효율(기울기) 비교", fontsize=14)
axes[1].set_xlabel("일일 광고비 (원)")
axes[1].set_ylabel("일일 매출(원)")
plt.tight_layout()
plt.show()